
티스토리 뷰
이 포스팅은 웹 크롤링으로 특정 태그, 클래스로 부터 값을 가져오는 방법을 정리하는 포스팅입니다.
1. python으로 웹 크롤링하는 방법
웹 크롤링이 필요할 때 python을 많이 사용합니다. 그 이유는 쉽고 빠르게 웹 크롤링할 수 있는 BeautifulSoup 라이브러리가 있어서 인데요. BeautifulSoup를 사용하여 간단히 웹 크롤링하는 방법을 알아보겠습니다.
Beautiful Soup는 Anaconda를 이용하여 Python을 설치하셨다면 기본적으로 설치되어있습니다. 만약, Anaconda 환경이 아니라면 아래 명령어로 Beautiful Soup를 설치해주세요.
pip install beautifulsoup4BeautifulSoup는 HTML 페이지의 웹소스를 쉽게 파싱 할 수 있도록 도와주는 라이브러리입니다.
웹 크롤링 하기 위해서는 beautifulsoup4와 urllib.request를 사용하여합니다.
그럼 간단하게 하나의 예제로 웹 크롤링을 해보겠습니다.
예제로 네이버 스마트 스토어의 한 페이지에서 제목을 가져오는 코드를 만들어 보겠습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup우선 두 개의 라이브러리를 import 합니다.
html= urlopen("https://smartstore.naver.com/sangkong/products/4762917002")
bsObject = BeautifulSoup(html, "html.parser")urlopen을 사용하여 해당 페이지의 HTML 소스를 가져옵니다.
그리고 BeautifulSoup를 사용하여 파싱 합니다.
bsObject를 출력해보면 페이지의 Html 소스를 확인할 수 있습니다.
이제 우리는 여기서 bsObject를 사용하여 특정 태그의 요소들을 뽑아 보겠습니다.
네이버 스마트 스토어의 html 코드를 확인해보면 strong 태그에 각종 정보들이 있는 것을 확인할 수 있습니다.
그래서 strong 태그를 모두 찾아보겠습니다.
bsObject.find_all("strong")
위와 같이 strong 태그들 목록이 나오는 것 확인할 수 있습니다.
여기서 title_simplebuy 클래스를 가져와보겠습니다.
bsObject.find_all("strong",{"class": "title_simplebuy"})
find_all로 찾게 되면 배열로 결과가 리턴됩니다.
그래서 이렇게 하나의 요소만 있을 때는 find로 하여 바로 object를 받을 수 있게 하면 좋습니다.
bsObject.find("strong",{"class": "title_simplebuy"})
이제 여기서 태그 안에 있는 text만 추출하겠습니다.
추출하는 방법은 간단합니다.
title_tag = bsObject.find("strong",{"class": "title_simplebuy"})
title_tag.text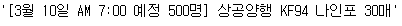
이렇게 간단하게 추출할 수 있습니다.
지금까지 BeautifulSoup의 기본적인 기능만 알아보았습니다.
웹 스크롤링을 이용하여 image 수집, 댓글 수집, 기사 수집 등 할 수 있습니다.
추가적인 내용은 공식 홈페이지를 확인하시면 좋습니다.
저도 앞으로 웹 크롤링으로 서비스를 만들어 보기 위해 계속하여 관련된 포스팅을 진행하겠습니다.
이번 공부는 여기까지!!
참고 사이트
'python' 카테고리의 다른 글
| [python] pymongo 활용 MongoDB CRUD (0) | 2020.03.09 |
|---|---|
| [Jupyter] Markdown 문법, 태그 사용법 (0) | 2020.03.01 |
| [Mac] jupyter 단축키 모음 (0) | 2020.02.26 |
| [python] 웹 크롤링 - 네이버 스토어 상품명, 가격 가져오는 함수 만들기. (0) | 2020.02.24 |
| numpy csv 파일 읽기, 쓰기 - loadtxt, savetxt, npy 형식 저장 (0) | 2020.02.21 |
- Total
- Today
- Yesterday
- k8s metrics-server running
- LeetCode 알고리즘 공부
- 노드
- LeetCode 30일 챌린지
- Java
- LeetCode 5월 챌린지
- 리엑트
- 30 Day LeetCode Challenge
- GPTGOT
- React 프로젝트 생성
- numpy
- Java leetcode
- git
- 파이썬
- Node
- 버츄얼스튜디오코드
- k8s metrics-server
- Component
- CHATGOT
- 에라토스테네스
- 넘파이
- 머신러닝
- vscode
- react
- 퍼셉트론
- 지도학습
- 파이썬 numpy
- LeetCode 풀이
- GPT서비스
- Python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |